Everyone is building multi-agent systems. Very few of them are safe to run against a real codebase and a real cloud bill.
If you point a typical orchestrator at a large repo with Claude Code, Copilot, or OpenAI behind it, a single mis-prompted critic can silently:
readorglobthe entire repository on every round- keep going long after you have mentally spent your budget
- leave you with no clear record of what happened or how much it cost
Most frameworks treat cost and tool safety as your problem. They give you a delegate hook, you wire in whatever you want, and if it melts your bill that is on you.
I wanted something different: a trust layer that makes multi-agent architecture reviews predictable, auditable, and safe by default.
That is what Archmesh is.
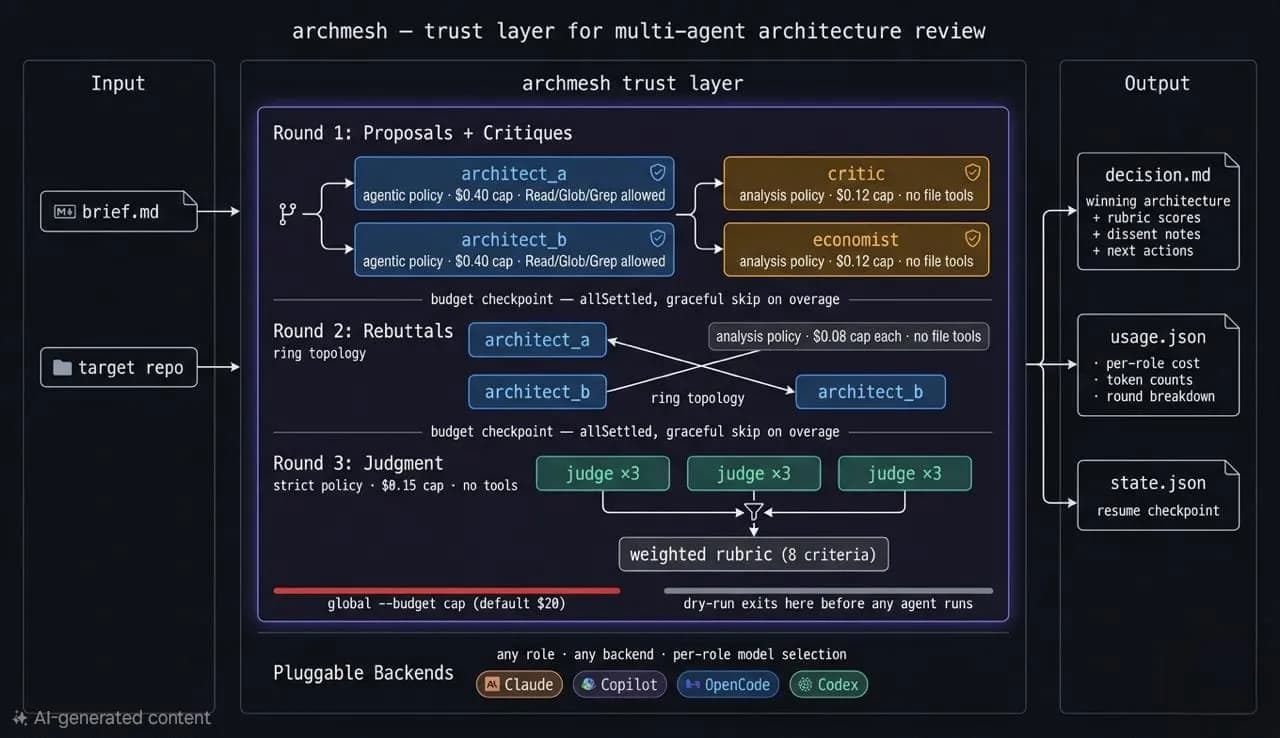
What Archmesh does
Archmesh runs a structured architecture review as a three-round multi-agent debate:
- Two AI architects propose competing designs.
- A critic and an economist challenge them.
- Each architect rebuts the other proposal.
- A judge ensemble scores everything on a weighted rubric and picks a winner (or synthesizes a hybrid).
Every role:
- runs under a hard USD cap
- is bound to a tool policy that controls what it can touch
Under the hood, Archmesh orchestrates locally installed tools like Claude Code, OpenCode, Copilot, and Codex via their TypeScript SDKs. It does not care which models you use; it cares how much they cost, what they are allowed to do, and when they must stop.
Why not just use Argue / LangGraph / AutoGen?
There are great orchestrators out there. Argue has a clean harness-agnostic design, and LangGraph/AutoGen provide flexible graphs and callbacks.
But when you look specifically at cost and tool safety, there is a gap.
Archmesh is opinionated exactly where those systems are hands-off:
| Argue | LangGraph / AutoGen | Archmesh | |
|---|---|---|---|
| Hard per-role USD caps | Delegate responsibility | Partial (callbacks) | Enforced before each call |
| Tool allowlist / blocklist | None | None | Per-role profiles |
| Dry-run cost estimate | None | None | Static cap sum, exits before any API call |
| Repo-scan prevention | None | None | Non-agentic roles blocked from file tools |
| Graceful degradation | Often all-or-nothing | Partial | Promise.allSettled across all roles |
| Debate topology control | Yes | No | ring / tournament / full |
| Structured schema validation | None | Partial | Zod-validated every round |
| Resume interrupted runs | None | Often manual | state.json checkpoint and archmesh resume |
If you want to run a serious architecture review against a real repo, with predictable spend and strong tool guardrails, you need more.
Hard cost contracts and tool guardrails
Archmesh treats cost and permissions as first-class configuration, not an afterthought.
Per-role budget caps
Each role has its own USD ceiling:
- Architects: 0.40
- Critic: 0.12
- Economist: 0.12
- Judges: 0.15 each
- Rebuttals: 0.08 each
Caps are enforced before each SDK call. If a role hits its limit, Archmesh skips that role and carries on with the rest of the mesh. One over-budget agent never kills the whole run.
Tool policy profiles
Tool usage is controlled by three built-in profiles:
agentic:Read,Glob,Grep(read-only repo exploration)analysis: no file tools; prompt context onlystrict: no tools at all; pure structured completion
By default:
- Architects are
agentic - Critic and economist are
analysis - Judges are
strict
Destructive tools (Write, Edit, Bash, WebSearch, etc.) are blocked in every profile.
You can override policies per role on the CLI, but you always know exactly which roles can touch your repo and which cannot.
Adapter safety model
Not every backend exposes the same level of control, so Archmesh is explicit about where guarantees come from:
- Claude: uses the Claude Agent SDK with
allowedTools/disallowedTools. If a tool is blocked there, the model cannot call it, regardless of what the prompt says. - Copilot: uses an
allowExplorationflag to influence whether tool-calling context is injected, but enforcement is prompt-level, not API-level. - OpenCode / Codex: pass a
toolsoverride; enforcement depends on the provider.
MCP connectors (docs, GitHub, Jira, etc.) are wired into the Claude adapter only, via the SDK mcpServers support.
If you care about hard guarantees, pair high-risk roles with Claude. Other adapters are clearly labeled as best-effort enforcement.
See your bill before you run: --dry-run
Archmesh ships with a dry-run mode that computes a worst-case spend estimate and exits without calling any agents:
archmesh run brief.md --repo ./myproject --dry-run \
--model-architect-a claude-sonnet-4-20250514 \
--model-architect-b claude-sonnet-4-20250514 \
--model-critic claude-sonnet-4-20250514 \
--model-economist claude-sonnet-4-20250514 \
--model-judge claude-sonnet-4-20250514
Output looks like:
=== Agent Configuration ===
repo: /Users/you/myproject
architect_a: claude -> claude-sonnet-4-20250514 (cap $0.40)
architect_b: claude -> claude-sonnet-4-20250514 (cap $0.40)
critic: claude -> claude-sonnet-4-20250514 (cap $0.12)
economist: claude -> claude-sonnet-4-20250514 (cap $0.12)
judge_1: claude -> claude-sonnet-4-20250514 (cap $0.15)
rebuttals (x2): max $0.16
Total worst-case: $1.35 (capped by --budget 5)
Effective cap: $1.35
Dry run - exiting without calling any agents.
How does this estimate work?
- It is the static sum of configured per-role caps, clipped by the global
--budget. - It does not try to simulate token pricing or model-specific usage.
In practice, real runs usually land around 40-70% of that ceiling depending on repo size and brief complexity.
Full cost audit: usage.json
Every run writes a usage.json and prints a summary table:
=== Usage Summary ===
round 1 / architect_a $0.1823 (12450 tokens)
round 1 / architect_b $0.2104 (14230 tokens)
round 1 / critic $0.0612 (8100 tokens)
round 1 / economist $0.0891 (9800 tokens)
round 2 / rebuttal-architect_a $0.0421 (5200 tokens)
round 2 / rebuttal-architect_b $0.0387 (4900 tokens)
round 3 / judge (x3) $0.1203 (15600 tokens)
total $0.7441
usage.json is plain JSON, so you can feed it into observability or FinOps tooling.
A concrete safety example
Here is what happens if you explicitly restrict the critic and they try to scan the repo anyway:
archmesh run brief.md --repo ./myproject \
--policy-critic analysis \
--model-architect-a claude-sonnet-4-20250514 \
--model-critic claude-sonnet-4-20250514 ...
Under the hood, the critic is backed by Claude with:
disallowedTools: ["Task", "Read", "Glob", "Grep"];
Even if the prompt says “read all files under src/”, the SDK will reject calls to those tools. If the critic also hits their $0.12 cap, Archmesh logs and skips that role:
critic skipped (budget exceeded: $0.12)
economist completed $0.09
The run continues to rebuttals and judgment using whatever critiques are available.
How the review mesh actually runs
Conceptually, the control plane looks like this:
brief.md + target repo
↓
role prompt builders <- skills injected (--skills-dir)
<- connectors appended (--connectors)
↓
adapter calls <- tool policy enforced (allowedTools / disallowedTools)
<- per-role USD cap checked before each call
↓
Zod schema validation <- malformed output skipped, run continues
↓
ensemble scoring <- weighted rubric applied; judges never see totals
↓
persisted artifacts -> decision.md · usage.json · state.json
The three rounds are:
- Proposals and critiques (parallel)
- Rebuttals (topology-driven)
- Judgment (ensemble)
You end up with a decision.md that includes the winning architecture, rubric scores, dissent notes, and next actions, plus raw JSON artifacts and a resumable state.json.
Quick start
Install:
npm install -g archmesh
# or
npx archmesh run ...
Make sure at least one backend is installed locally (Claude, Copilot, OpenCode, or Codex).
Then:
- Run the wizard.
archmesh init
- Write a brief.
Create a brief.md describing the system you want reviewed: context, constraints, and questions. There are examples under src/__fixtures__/briefs/ in the repo.
- List models.
archmesh models
archmesh models claude
archmesh models opencode
- Run a review.
Each role can use a different backend and model. This is where mixing providers pays off — you get genuine adversarial diversity rather than one model agreeing with itself.
Adversarial diversity — Claude vs Codex architects, Gemini critic, 3-judge panel:
archmesh run my-brief.md --repo /path/to/project \
--architect-a claude --model-architect-a claude-opus-4-6 \
--architect-b codex --model-architect-b o3 \
--critic opencode --model-critic google/gemini-2.5-pro \
--economist claude --model-economist claude-sonnet-4-6 \
--judge claude --model-judge claude-sonnet-4-6 \
--judges 3 \
--topology tournament \
--budget 15
Cost-optimised — fast models everywhere, single judge, hard $3 cap:
archmesh run my-brief.md --repo /path/to/project \
--architect-a claude --model-architect-a claude-sonnet-4-6 \
--architect-b opencode --model-architect-b openai/gpt-4.1 \
--critic opencode --model-critic openai/gpt-4.1-mini \
--economist opencode --model-economist google/gemini-2.5-flash \
--judge copilot --model-judge gpt-4.1 \
--judges 1 \
--topology ring \
--budget 3
GPT vs Claude — pure adversarial, critics on opposite providers, 5-judge ensemble:
archmesh run my-brief.md --repo /path/to/project \
--architect-a claude --model-architect-a claude-opus-4-6 \
--architect-b copilot --model-architect-b gpt-4.1 \
--critic opencode --model-critic anthropic/claude-sonnet-4-6 \
--economist opencode --model-economist openai/gpt-4.1 \
--judge claude --model-judge claude-sonnet-4-6 \
--judges 5 \
--topology full \
--budget 20
- Inspect the run.
Look under runs/<timestamp>/ for proposals, critiques, rebuttals, scores, decision.md, and usage.json.
Beyond the CLI: skills, connectors, and A2A
Archmesh is intentionally small at the core. On top of that you can optionally add:
- Skills packs: per-role markdown files that inject domain expertise (e.g., “prefer Kubernetes-native,” “model TCO over 24 months”).
- MCP connectors: give the mesh access to your docs, GitHub, or issue tracker via the Model Context Protocol.
- A2A server: expose Archmesh as an Agent2Agent-compatible HTTP service so other agents can call it programmatically.
Those are optional. A simple archmesh run does not need any of them.
What Archmesh guarantees — and what it does not
Archmesh does:
- enforce per-role USD caps (especially strong on Claude via SDK-level enforcement)
- give you a global
--budgethard stop - block destructive tools on the Claude adapter
- refuse to run without your explicit models and policies
- validate all agent outputs against Zod schemas
- persist full usage and state for audit and resume
Archmesh does not:
- magically make unsafe models safe if their SDK ignores tools
- predict token usage with provider-level pricing
- stop a model from reasoning about content it already saw in a previous turn
The goal is not perfect safety. The goal is predictable behavior with explicit contracts about what the system will and will not do.
Where this is going: Archmesh Hub
Right now most AI code analysis is ephemeral. Someone spends money, gets a result, pastes it in Slack, and the knowledge disappears.
A natural next step is a public archive of architecture reviews for open-source repos — a shared technical knowledge layer focused on architectural reasoning rather than stars, issues, or raw code search. That is Archmesh Hub, and it is what comes after the CLI is solid. More on that in a follow-up post.
Try it
- Code: github.com/KBoudich/archimesh
- Install:
npm install -g archmesh - Run:
archmesh initthenarchmesh run brief.md --repo . --budget 2 ...
I would love feedback from people running real systems: what guardrails are you missing, and what other trust primitives should exist for multi-agent tools?